Python 实现 AI 拟声: 5秒内克隆您的声音并生成任意语音内容
快速开始 (新手友好版)
本快速开始教程是以Windows为例的,假设不做任何训练(节省几小时甚至几天时间),假设你对python等开发环境也不熟悉,也可能没有支持CUDA的GPU
安装
如果已经确认安装过,请忽略该步骤
拉取本代码库
安装Anacodna, Python 3.8 或更高,参考中文教程,在Anaconda中创建并切换到独立虚拟环境后,进行以下步骤。
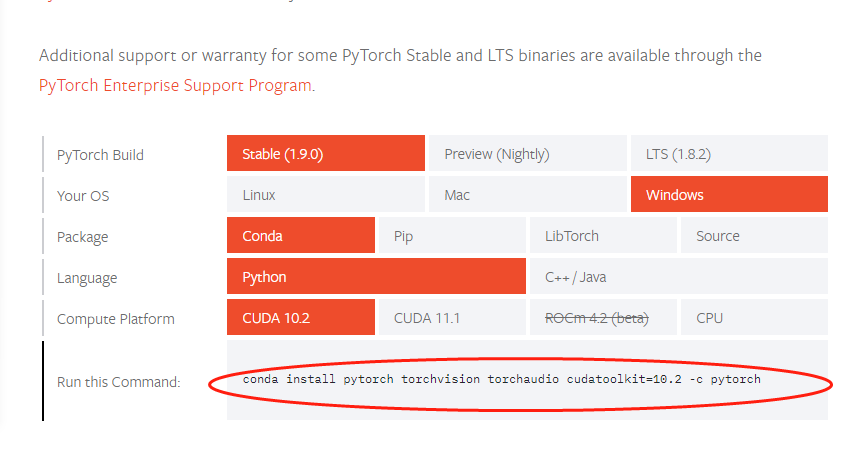
安装 PyTorch, 直接官网下载。如果GPU不支持CUDA,请默认选择。
验证本步骤是否成功:在系统任意路径下运行python,进入交互式编程界面后输入
import torch;, 回车,torch.cuda.is_available(), 回车。如果都是成功的话,可以进行下一步。
安装 ffmpeg。 1)下载 选择点击打开链接Windows对应的版本下载 2)解压 ffmpeg-xxxx.zip 文件到指定目录; 3)将解压后的文件目录中 bin 目录(包含 ffmpeg.exe )添加进 path 环境变量中; 4)进入 cmd,输入 ffmpeg -version,可验证当前系统是否识别 ffmpeg 以及查看 ffmpeg 的版本
运行pip install -r requirements.txt 来安装剩余的必要包。
确保本步骤不报错
- 安装 webrtcvad 用 pip install webrtcvad-wheels。
确保本步骤不报错
下载社区训练好的模型
在以下选择中下载模型
| 作者 | 下载链接 | 效果预览 |
|---|---|---|
| @miven | 百度网盘 请输入提取码 提取码:2021 | AI声音模仿,5秒钟克隆你的语音_哔哩哔哩_bilibili |
下载完成后,确保 xxx.pt 格式的文件放在代码库的 synthesizer\saved_models文件夹下,saved_models如不存在请新建
运行demo_toolbox
在代码库路径下,运行 python demo_toolbox.py -d .\samples 尝试使用工具箱, 由于没有下载任何数据集,这里的功能比较简单:
- 确保界面左边中间的 synthesizer 选择了上一步中 xxx.pt 文件对应的模型。
点击Record录入你的5秒语音
输入任意文字
点击 Synthesizer and vocode 等待效果输出确保界面左边中间的 synthesizer 选择了上一步中 xxx.pt 文件对应的模型。
点击Record录入你的5秒语音
输入任意文字
点击 Synthesizer and vocode 等待效果输出确保界面左边中间的 synthesizer 选择了上一步中 xxx.pt 文件对应的模型。
点击Record录入你的5秒语音
输入任意文字
点击 Synthesizer and vocode 等待效果输出确保界面左边中间的synthesizer选择了上一步中xxx.pt文件对应的模型。 - 点击
Record录入你的5秒语音 - 输入任意文字
- 点击
Synthesizer and vocode等待效果输出
本站所有文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱: 1981580298@qq.com
上一篇:夜读 | 用热爱去抵挡岁月漫长
下一篇:夜读 | 别为难自己




